Scalable data processing
“I’ve heard you like scalability, so what about some scalability to scale your scalability?”
The use-case of this architecture is to provide a very scalable data processing pipeline that handles both authentication with the data provider and processing the data into flexible datasets. For the purpose of this specific setup, the consumption of the data itself (which is managed by a separate application) is outside of the scope.
In this specific setup we are talking about authenticating with web sockets , processing this data through an application layer and writing this data into either our ClickHouse or MongoDB datasets. Though there will not be much detail, I will describe all three layers individually.
Though the design derives heavily from the Microservices architecture, we have tried to avoid some usual drawbacks of this architecture.
Namely;
- Mitigating partial failure of the communication between services
- Aggressive reduction of resource consumption due to what I will call ‘management services’
Though most of my experience with Microservices has been with Spring Boot (Java), for the purpose of this project we’ve focused on utilizing NodeJS as effectively as possible.
Establishing a Connection
The nature of this project makes it so that we consume a large set of identical WebSockets that all deliver data restricted to a single scope. Conveniently, the structure of this data is largely the same across all WebSockets. This connection layer is quite simplified. We use the containerization software Docker, which offers an orchestration layer that can handle horizontal scalability perfectly. Basically, it has integrated functionalities that manage the different services that you deploy under it. My drawing skills are a bit rudimentary but it is a nice vehicle to explain what I mean.
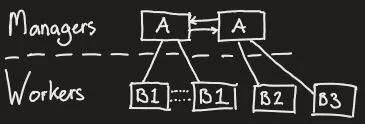
The Managers layer uses the Docker Manager Hosts to manage the set of worker services. The Managers in this case handle Load balancing, the connection to the internet and the distribution of tasks among the nodes of their swarm. In the case of this particular setup, the application on these managers also monitors the health (network stability, capacity consumption, connectionStatus, errors) of the workers. The manager is at liberty to deploy new workers (nodes) should capacity demand it, or kill nodes that are no longer required or malfunctioning. All workers consist of identical applications fed by metadata (such as credentials, identifier, etc.) from the Manager that deploys their instance.
The workers are very basic applications. They authenticate with the websocket, retrieve the desired information, and pass it on to the data processing layer. They are all identical, bar the contextual data. Data is retrieved and cached in worker-allocated RAM memory. We leverage cache warming to reduce the data-stream to just the new or changing data points.
Hypothetically we should have no issue deploying multiple instances of the same worker on the same websocket in the future. Currently this is something that the data broker does not permit. A workaround could be to separate the authentication service from the data retrieval service, but this is a level of complexity that we are currently trying to avoid.
Processing the data
The workers create a data-stream based on new and changing data points. This is ideal because it is relatively light weight, but also a necessity as we are working with ‘real-time data’. Though real-time is obviously a bit of an abstract term in terms of data processing, in this case we mean: least amount of time possible. *
*Logically the time between data creation and visualization would be better without this application layer in between, but the nature of the data ingestion platform does not permit this setup.
The application layer consists of a couple of JavaScript based applications that retrieve and then handle different types of data from the cached datasets of the workers. Part of this data is mapped into ClickHouse datasets where we do different sorts of calculations and aggregations to create a reporting set for dashboards. Other parts of the data are pushed into MariaDB/MongoDB databases as-is for reporting purposes, and other parts of this data are livestreamed to geographical interfaces (think; asset-tracking).
Think of the Workers layer as a buffet of a huge variety of food. The application layer picks and chooses the relevant dishes and ingredients to combine them into the meal (dataset) that is required by the customer. The reason these dishes are handled by different waiters(applications) is because some dishes are more complex/ take more time than others, and you do not want to leave people waiting unnecessarily.
Organising the datastores
Now, I am sure there is a very nice, high-tech NO-SQL data lake that we could’ve set up with a nice set of data APIs that meets a list of buzzwords. And speaking frankly I hope to be writing an article about how I implemented that in a year. But because of our internal skillsets and time to market, that was a bridge too far.
Instead, we opted for some proven database technologies depending on the use case of the dataset. In case of our reporting data, this means the Application Layer pushes all its data to a denormalised ClickHouse database. The nature of the technology provides native means to scale horizontally with replication and vertically with sharding that is inheritent to the ClickHouse solution. Currently we are finding datasets of 80 million rows to be of little consequence to the application in the grand scheme of things (time between data generation and data visualisation). It does require some tuning to make sure that the data you use is as light-weight and reporting ready as possible before the data visualisation application gets its hand on it.
For our more ‘malleable’ data, we let the Application Layer push data to a MongoDB instance that is also being enhanced by the backend data of our platform. It provides a bridge between the data of the data provider and the operational context data.
The future of this project
My team is now working hard on future iterations of this project, which gives me time for retrospection and introspection. Call it lessons learned. Because of the nature of this project, I do not want to divulge too much of the platform’s weaknesses, or ways of improving upon it until we have done those changes ourselves.
For the sake of scientific research I am, however, very interested in building a similar platform again, with Azure Cosmos DB. Specifically to find out;
- How can we leverage the advantage of no-ETL analytics to process asset data at a larger scale? How would the performance of this solution compare to our current setup?
- How can we leverage the native MongoDB APIs to provide ‘on demand’ reporting and Data Science datasets to both internal and external customers? And by extension, what would this do in regards to our product development cycle?
Perhaps we will find the answers to these questions someday.
Thank you for reading.